Visual Voice Activity Detection
The VVAD-LRS3 Dataset for Visual Voice Activity Detection

Data Source: LRS3 Dataset
Thousands of sentences from TED/TEDx Videos
Click to view dataset
Preprocessing
Extract 38 Frames Per Video (1.52s Window)
Data Samples
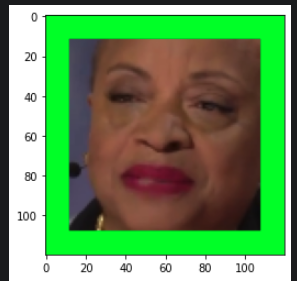
Positive Sample (Speaking)
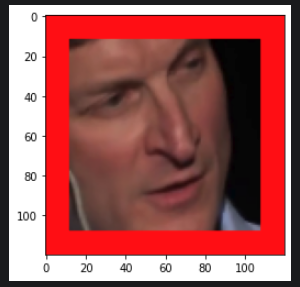
Negative Sample (Not Speaking)
Face Crops
Full Face Region
Lip Crops
Mouth Region Only
Approach 1: Deep Learning Classification
Embedding Generation
Generate feature embeddings from Face/Lip sequences using various models.
ResNet50
VideoMAE
ViViT
VGG16
Classifier Training
Train classifiers on the generated embeddings to detect speech activity.
Feedforward CNN
FCN
Output & Evaluation
Binary classification and performance measurement.
Metrics:
Accuracy, Precision, Recall, F1-Score
Quantitative Results (Face Modality)
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNet50 | 73.80% | 0.72 | 0.72 | 0.72 |
| VideoMAE | 84.50% | 0.82 | 0.83 | 0.84 |
| ViViT | 83.00% | 0.82 | 0.82 | 0.83 |
| VGG16 | 81.20% | 0.78 | 0.81 | 0.80 |
Approach 2: Generative (Video-LLaVA)
Data Conversion
Recompile 38-frame image sequences back into MP4 video clips using OpenCV.
Video-LLM Processing
Process video clips and a text prompt to generate a descriptive response.
Model: Video-LLaVA-7B-hf
Prompt: "Analyze this video... Is the person speaking or silent? Describe the visual cues."
Output & Analysis
Qualitative, descriptive output in natural language.
Speaking: "The person... appears to be speaking. Their mouth is open and moving..."
Not Speaking: "The person... is silent. Their lips are closed and still..."